终章 · AI Agent 与科研
多智能体、AI 做科研、科研 Skill 实践
AI 扮演的角色一直在变:最早是一个口令一个动作的工具,后来开始讲人机协作,现在已经出现大量有极强自主性、能独立完成任务的 Agent。它能不能做科研,这一章用证据来回答,既有振奋人心的现场,也有该泼的冷水,最后落到一套可以直接复用的科研 Skill。
当多个 Agent 相遇:协作、对抗与社交#
进入科研前先看 Agent 之间会发生什么。协作方面,研究者用有向图描述多 Agent 的协作结构,一个反直觉的发现是接龙式效果通常最差、互动更多的 Mesh 结构反而更好;清华的 MACNET(2406.07155MACNET)把这推到 1000 个以上 Agent 协作,发现了"协作缩放律"——性能随数量呈逻辑斯蒂增长后饱和,且不规则拓扑优于规则拓扑。对抗方面,在狼人杀里身为狼人的 Agent 甚至会为骗过村民而投票给队友;MARO(2601.12323MARO)发现教 Agent 玩剧本杀居然能同时提升它的数学推理和指令遵循能力。社交方面,已经出现了专给 AI Agent 加入的社群平台,但分析发现多数行为背后仍有人为操控痕迹。

这是"协作缩放律"的原始证据(MACNET 论文 Figure 7)。无论链、星、树、网状、分层还是随机拓扑,产出质量都随 Agent 数量呈 S 形(逻辑斯蒂)增长——先平、再陡升、最后饱和;其中右下角的随机(不规则)拓扑爬得最高,正好印证"不规则拓扑反而优于规则拓扑"。
AI 真能做科研吗:三个现场#
现场一,1 小时写出一篇论文。 斯坦福政经学家 Andrew Hall 用 Claude Code,像导师指导研究生一样引导 AI 复现自己 2020 年发在 PNAS 的论文并扩展到 2024 年新数据,还请了一位博士生做无 AI 的独立审计当标准答案。结果是 Claude 的结果与人工高度一致(相关性超过 0.999),不到 1 小时、约 10 美元完成了人工要数天的工作。由此他提出"100x 研究机构"愿景:研究不再是定格的论文,而是持续自动更新的活体研究。
现场二,通宵自主做实验的 AI。 Karpathy 的 autoresearch 项目给 AI 一套真实但很小的训练环境,让它通宵自主迭代——改脚本、固定 5 分钟训练、看指标、保留或丢弃、重复。人类只编辑一个提供上下文的 program.md(他形容为超轻量的 skill),完全不碰代码。
现场三,AI 当一作、AI 审稿。 已出现完全由 AI 主导的学术会议 Agents4Science(2511.15534Agents4Science),要求 AI 必须是第一作者和主要贡献者并负责审稿。现实中 AI 审稿也已进入 ICLR 2026 等顶会流程。
一盆冷水:理念惊艳,执行褪色#
这是终章最重要的一组证据,也是"AI 的点子很多是唬人的"这一判断的实证来源。斯坦福同一个团队做了一对双联研究:
盲评点子本身:AI 在新颖性、兴奋度上显著高于人类专家。
柱高为示意,非精确分值。来源:arXiv 2409.04109 与 2506.20803。
第一篇(2409.04109理念阶段)招募 100 多位研究者盲评点子,AI 在新颖性和兴奋度上被判定显著高于人类专家。第二篇(2506.20803执行之后)让 43 位专家每人花 100 多小时真正执行随机分配的点子,写成短论文再盲审,结果执行之后 AI 点子在所有维度都比人类点子下降得更多,理念阶段的领先优势被完全抹平,多个指标甚至反转成人类领先。原因是 AI 有时只是堆砌新颖的词汇,听着惊艳,可真动手做就发现行不通。
什么时候 AI 科研才靠谱:验证、反馈、闭环#
把乐观和冷水放一起,会得到一条清晰的分界线:AI 科研靠不靠谱,取决于有没有严格的验证机制,以及模型能力有没有跨过某个阈值。有验证器就行:DeepMind 的 Gemini Deep Think 配了一个自然语言验证器,迭代"生成、验证、修订",还能承认自己解不出来,结果它对 700 个 Erdős 猜想做半自主评估、自主解出其中 4 个开放问题。有真实反馈闭环就行,但模型得够强:Owkin(2603.26177Owkin)在真实生物实验里做了 800 次重复,证明 AI 确实能从实验反馈中学习(有反馈时发现量平均增加 53.4%,打乱反馈后增益消失),但前提是模型能力跨过阈值——从 Sonnet 4.5 升到 4.6,原本不显著的学习效应才变显著。
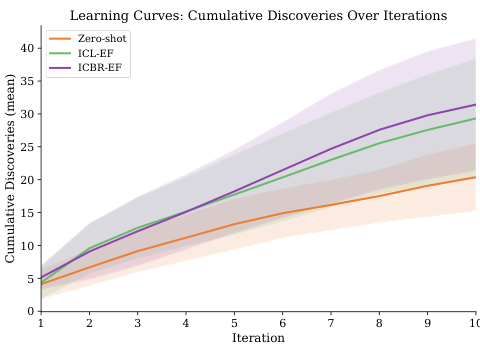
横轴是迭代轮次,纵轴是累计发现的有效特征数(Owkin 论文 Figure 2)。带真实实验反馈的两条曲线越往后越把无反馈的基线拉开——这就是"AI 能从实验反馈中学习"的直接证据;而一旦把反馈打乱,这道差距就消失,说明学到的是真信号而非噪声。
人类把关:STOP-AND-CHECK#
贯穿所有靠谱实践的一条共识是:AI 当合作者、力量倍增器,人类保留判断与验证权。最好的范本是 Hall 给 Claude Code 的那份任务说明书:它把任务分成若干阶段,每个阶段之间设了多个 🛑 STOP-AND-CHECK 检查点——Agent 每完成一步,必须先汇报已完成的内容、给出关键产物、列出疑虑,然后等人类批准才能继续。这正是 Planner-Generator-Evaluator 和 RO loop 在科研场景的落地,只不过这里的 Evaluator 是人类。
把这些原则——证据可溯源、人类把关、不覆盖原始文件——固化进一个 Agent 让它每次都自动遵守,就是 Skill 的用武之地。
科研 Skill 实践:把一位严谨导师的习惯编码成提示词#
前面三级工程都在讲原理,这一节落到一个可以直接装上就用的真实案例:一套面向中国科研工作者(尤其是光电信息科学与工程方向)的中文优先学术 Skill 包,把"读论文、做分析、写论文、出 Word 和 PPT"的全链路拆成三个互补技能。
| Skill | 管什么 | 触发场景 |
|---|---|---|
| research-writing-skill | 论文正文写作、修订、润色、审稿回复 | 输出是 prose / LaTeX / Markdown 手稿 |
| office-academic-skill | 论文阅读报告、答辩或组会 PPT、可编辑 Word/PPTX | 主交付物是 Word 或 PPT |
| scientific-toolkit-skill | MATLAB、Python 科学计算、统计、仿真、出图、文献检索 | 要写代码、画图、跑仿真、查文献 |
这套 Skill 的价值不在某段惊艳的提示词,而在它示范了一套靠谱、可溯源、不乱删的垂直 Agent 组织方法论。它把前面讲过的概念全用上了:
一、路由层提示词决定何时出场,对应 Skill 的 description 决定能否被触发。 三个 Skill 的 description 都用同一个三段式模板:先枚举能力,再写 Use when ... 列出触发场景,最后写 Preserve ... 把关键约束前置。每个 Skill 正文还显式写了"什么情况该用别的 Skill"的互斥规则,避免三个技能争抢同一任务。
二、渐进式披露把重资源下沉到 references。 SKILL.md 正文只放工作流和约束,细节全部放进 references/ 子文件,正文里只留"需要时再读某文件"的指针。scientific-toolkit 甚至嵌套了 23 个各带自己 SKILL.md 的子技能(matplotlib、scikit-learn、sympy、pymatgen、qutip 等),平时只占一行描述,命中才加载。
三、反幻觉加证据分级,正是那盆冷水的工程化解药。 三个 Skill 反复强调一条最强约束:绝不编造 DOI、作者、期刊、实验值、图号、页码、结论、物理参数。并要求把信息分层打标签,比如区分"原文或已有数据""用户确认内容""根据上下文推断""建议性扩展"四类。这套来源分级标注直接对抗 LLM 在学术场景最危险的失败模式——把推测当事实。
四、质量门禁加非破坏性安全规则,对应能力边界和人类把关。 每个 Skill 末尾都有强制的交付前自检;安全规则更是和数据安全红线高度一致:绝不暴露 API key,绝不覆盖原始数据、代码、Word、PPT、图(一律写带时间戳的版本化输出),未经明确确认不删除或递归清理用户文件,PPTX 必须在副本上操作。
五、把领域知识也写进提示词。 scientific-toolkit 在"领域默认"里点名了 BOTDR、BOTDA、色散、去卷积、光纤传感、光谱学、探测器数据、标定与不确定度,让模型自动偏向光电领域,而非给泛泛的答案。
这套 Skill 本质上是把一位严谨的中文科研导师的工作习惯,编码成了分层提示词系统:用 description 做路由,用正文做纪律,用 references 做工具库,再用反幻觉标签、质量门禁、非破坏性安全规则,把 LLM 在学术场景最容易翻车的三个点(编造、不自检、覆盖原始文件)逐一封堵。这套方法论可以迁移到任何需要靠谱、可溯源的垂直 Agent 场景。
收尾:把 Agent 当成"有能力的实习生"#
从 Shell 讲到自主科研,最后回到那个最朴素也最准的比喻:AI Agent 就像一个有能力、但还不成熟的实习生。它有真本事,也会犯错、会鲁莽、会幻想自己做完了、会被压缩搞丢关键指令而删你邮件、会堆砌漂亮词汇糊弄你。对待实习生的正确态度,是给他一个安全的环境去学习和成长:
- 给他独立、隔离的环境——独立电脑、独立账号,别和敏感资料混在一起。
- 给他清晰的引导——一份好的
CLAUDE.md、一套合适的 Skill 和工具。 - 给他可逆的边界和把关点——重要操作先备份、先确认。
人类的角色正在从亲自动手做,转向设定任务目标、引导 Agent、评估其产出、做架构与问题分解。